Autoware中topic_state_monitor模块调研
一、topic_state_monitor模块简介
此节点用于监控任意话题是否存在异常,例如超时和低频率。话题的诊断结果将通过ROS Diagnostics发布诊断信息。
- 输入:任意名称、任意类型的话题
- 输出:
/diagnostics诊断信息
二、topic_state_monitor模块启动流程
通过解析 topic_state_monitor 核心代码部分并逐级向上追溯,可得到 topic_state_monitor 模块完整的启动流程,如下图所示:
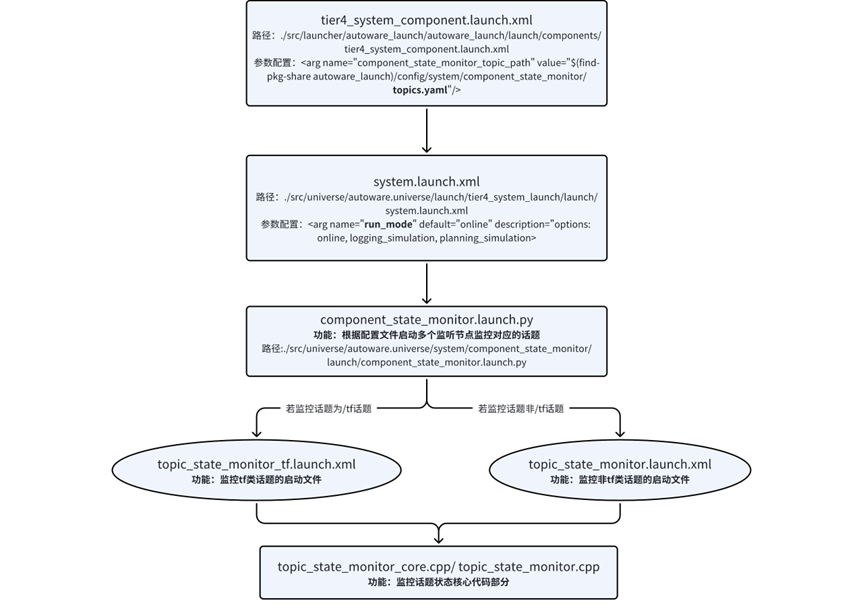
上层的两个
.launch.xml 文件主要配置了两个参数。一个是 tier4_system_component.launch.xml 中配置的 topics.yaml 文件路径。topics.yaml 文件内容是配置所有需要监控的话题信息以及监控阈值信息。配置文件的内容示例如下:
- module: control
mode: [online, logging_simulation, planning_simulation]
type: autonomous
args:
topic_type: autoware_control_msgs/msg/Control
best_effort: false
transient_local: false
warn_rate: 5.0
error_rate: 1.0
timeout: 1.0
- module: control
mode: [online, logging_simulation, planning_simulation]
type: autonomous
args:
node_name_suffix: control_command_control_cmd
topic: /control/command/control_cmd
topic_type: autoware_control_msgs/msg/Control
best_effort: false
transient_local: false
warn_rate: 5.0
error_rate: 1.0
timeout: 1.0
- module: localization
mode: [online, logging_simulation, planning_simulation]
type: autonomous
args:
node_name_suffix: transform_map_to_base_link
topic: /tf
frame_id: map
child_frame_id: base_link
best_effort: false
transient_local: false
warn_rate: 5.0
error_rate: 1.0
timeout: 1.0代码2-1 topics.yaml配置⽂件⽰例
配置文件的各个参数的解释如下:
| 名称 | 含义 |
|---|---|
module |
话题所属的模块 |
mode |
指定了配置适用的模式,通过设置 mode,可以控制配置文件在不同运行环境下是否生效 |
type |
指定话题的类型,根据不同的 type 分类,component_state_monitor 模块会分析 /diagnostics 诊断信息给出 /type/module 模块的状态(判断是否正常运行,消息类型为自定义的 ModeChangeAvailable) |
node_name_suffix |
节点名称的后缀,用于动态生成节点名称 |
topic |
指定要监控的目标话题的名称 |
topic_type |
指定目标话题的数据类型 |
best_effort |
指定是否使用 "Best Effort" QoS策略。如果设置为 true,意味着使用“尽力而为”策略,即消息传输尽力而为,可能会丢失消息。设置为 false 则表示采用 "Reliable" QoS策略,确保消息的可靠传输,但可能带来更高的延迟。 |
transient_local |
指定是否使用 "Transient Local" QoS策略。如果设置为 true,即使订阅者在发布时不存在,消息也会暂时保存在中间件中,直到订阅者连接。此策略适用于需要历史消息的场景。如果设置为 false,则采用普通的QoS策略,只有当前连接的订阅者可以接收到发布的消息。 |
warn_rate |
话题发布频率警告阈值,当话题的发布频率低于该值时,话题状态将被设置为 WarnRate,即警告状态 |
error_rate |
话题发布频率错误阈值,当指定当话题的发布频率低于该值时,话题状态将被设置为 ErrorRate,即错误状态 |
timeout |
这个参数指定如果话题订阅在超过指定的时间(单位为秒)内没有收到消息,话题状态将被设置为 Timeout |
frame_id |
坐标变换的父坐标系ID |
child_frame_id |
坐标变换的子框架ID |
window_size |
计算目标主题频率使用的窗口大小,例如,窗口大小为10表示计算过去10个发布周期的频率 |
uprate_rate |
定时器回调频率,用于设置更新和检查主题状态的频率 |
表2-1 topics.yaml配置⽂件参数解释
system.launch.xml 文件中设置了配置所选择的模式,根据模式的选择来监听不同的话题组。话题所属的模式在上述 topics.yaml 文件中设置。
<arg name="run_mode" default="online" description="options: online, logging_simulation, planning_simulation最终通过 component_state_monitor.launch.py 生成了一系列针对目标话题的监控节点。这些节点发布诊断数据到 /diagnostics 话题中。
三、topic_state_monitor模块运行效果
运行 Autoware 的规划demo样例后:
cd autoware
source ~/autoware/install/setup.bash
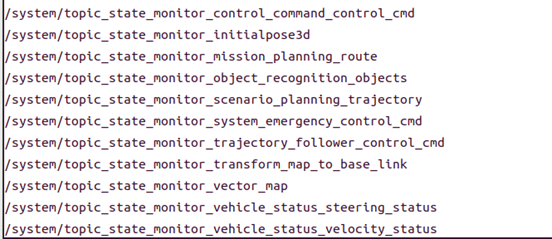
ros2 launch autoware_launch planning_simulator.launch.xml map_path:=$HOME/autoware_map/sample-map-planning vehicle_model:=sample_vehicle sensor_model:=sample_sensor_kit然后运行 ros2 node list 可以看到 topic_state_monitor 模块运行起来一些监控节点来对配置文件中的话题进行监控。监控节点名称为:“topic_state_monitor” + topic.yaml 中话题的 node_name_suffix 名称。
这些节点输出诊断信息到 ROS Diagnostics 诊断系统中,可以在 rqt_runtime_monitor 中看到诊断结果。
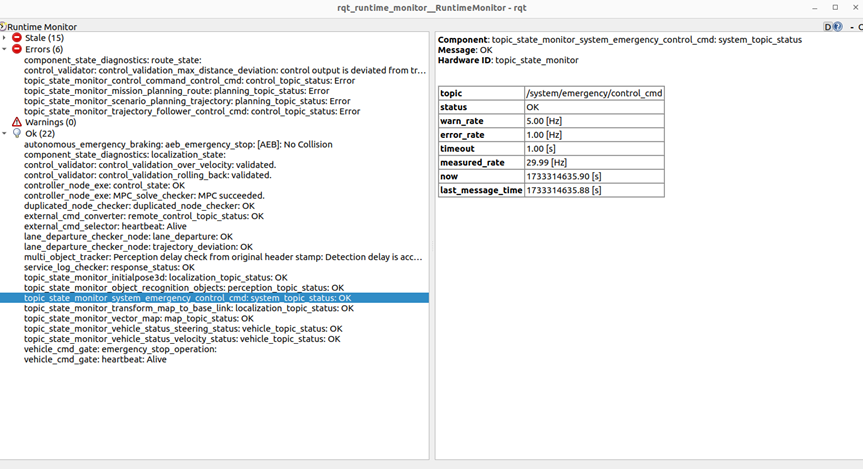
同时,component_state_monitor::StateMonitor 节点的 main.cpp 订阅 /diagnostics 话题并通过定时器周期性地检查不同模块整体的状态是否正常。输出的话题格式是 ~/type/module,例如,对于 type 为 launch 中的 map 模块,输出话题为 ~/launch/map。

话题输出的消息格式是自定义的 ModeChangeAvailable.msg 格式,用于表示某个模块是否可用。消息包含以下内容:
stamp:时间戳,表示消息生成的时间。available:布尔值,表示该模块当前是否有效。true表示模块正常,false表示模块不可用。
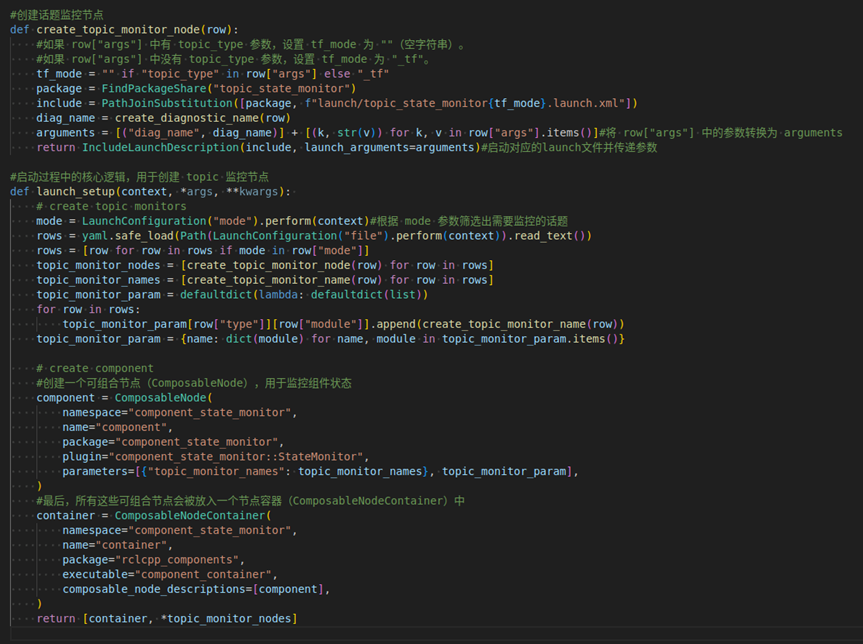
四、topic状态监控部分实现原理
分析源码后总结下来,其核心是通过 component_state_monitor.launch.py 对 config.yaml 文件中要监控的 topic 一对一创建一个 node。
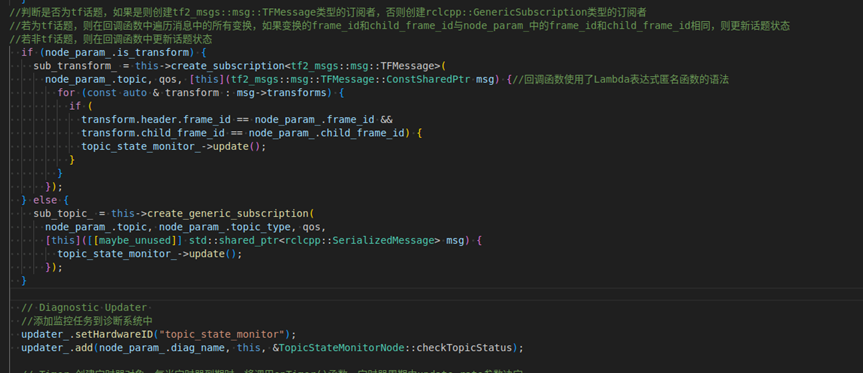
随后将 node 启动部分注册成一个插件,这样可以用同一个源码启动多个 node。在 node 源码中,根据监控 topic 是否为 tf 话题创建 tf 类订阅者和非 tf 类订阅者。这里针对非 tf 类 topic,使用了 rclcpp::SerializedMessage 一个通用的消息类型,表示经过序列化的消息。它不关心消息的具体内容,只是将消息传递为原始的字节流。
五、一些考量点
topic_state_monitor 模块可针对任意类型的 topic 生成一个 node 去监控 topic 的状态,通用性强。但如果需要监控的 topic 过多可能进程开销大,因此要对该模块对于性能的开销进行测试来判断是否可迁移到人形机器人上。
topic_state_monitor 模块采用了组合节点并将组合节点放入 container 中来启动一堆 node 去监控各个 topic。这样做的好处是将多个节点加载到同一个进程中,每个节点仍然保持独立的逻辑和功能,但它们可以更高效地共享数据和资源。这种方法不仅减少了通信延迟,而且降低了系统的整体资源消耗(例如,CPU时间内存使用)。
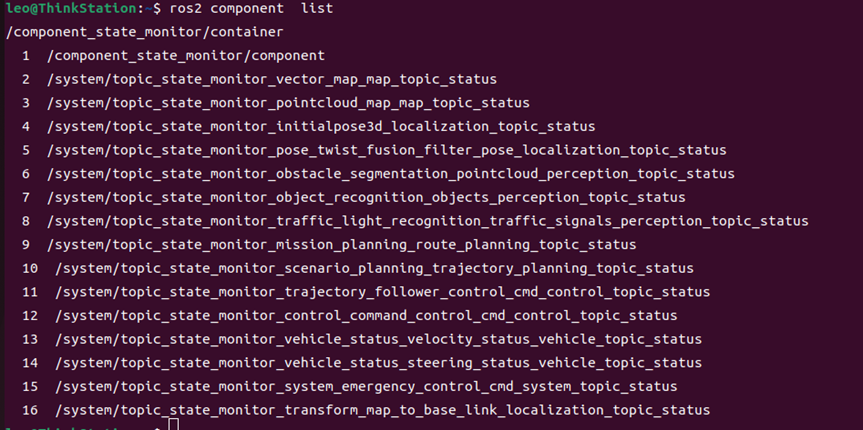
实际使用 Autoware 进行测试时发现,输入 ros2 component list 查看容器节点信息可知组合节点 /system/component_state_monitor/component 有被放入 /system/component_state_monitor/container 容器中。

但是查询系统进程资源占用情况时发现:启动的各个监控 node 并没有在同一个进程中进行,而是各自占用了一个进程,这样性能总开销过大。
猜测是启动文件中 node 的启动方式存在问题。经过分析发现问题出在 component_state_monitor.launch.py 启动文件对于 node 节点的启动是通过启动一个个 launch.xml 文件来生成监控 node 节点,并没有将 node 节点放入 container 容器中,因此占用了多个进程。
想要减少进程的占用,需要重构 component_state_monitor.launch.py 对于 node 节点的启动部分。修改后的代码如下:
from collections import defaultdict
from pathlib import Path
import launch
from launch.actions import DeclareLaunchArgument, OpaqueFunction
from launch.substitutions import LaunchConfiguration
from launch_ros.actions import ComposableNodeContainer
from launch_ros.descriptions import ComposableNode
import yaml
def create_diagnostic_name(row):
return f"{row['module']}_topic_status"
def create_topic_monitor_name(row):
diag_name = create_diagnostic_name(row)
node_name_suffix = row["args"]["node_name_suffix"]
# 替换非法字符,如冒号和空格为下划线(防止报错Couldn't parse remap rule: '-r __node......)
node_name_suffix = node_name_suffix.replace(":", "_").replace(" ", "_")
diag_name = diag_name.replace(":", "_").replace(" ", "_")
return f"topic_state_monitor_{node_name_suffix}_{diag_name}"
def create_topic_monitor_node(row):
diag_name = create_diagnostic_name(row)
# 基础参数
parameters = [{"diag_name": diag_name}]
# 根据是否为 TF 类话题,添加不同的参数
remappings = []
if "topic_type" in row["args"]:
# 非 TF 类话题
parameters.append({"topic_type": row["args"]["topic_type"]})
else:
# TF 类话题
parameters.append({"frame_id": row["args"]["frame_id"]})
parameters.append({"child_frame_id": row["args"]["child_frame_id"]})
# 其他参数
for k, v in row["args"].items():
if k not in ["topic_type", "frame_id", "child_frame_id"]:
parameters.append({k: v})
# 如果需要进行主题重映射,可以在这里添加 remappings
# 假设 YAML 文件中不包含 remaps 字段,因此 remappings 为空
# if "remaps" in row["args"]:
# for remap in row["args"]["remaps"]:
# remappings.append(remap)
return ComposableNode(
namespace="system",
package="topic_state_monitor",
plugin="topic_state_monitor::TopicStateMonitorNode",
name=create_topic_monitor_name(row),
parameters=parameters,
remappings=remappings # 目前为空
)
def launch_setup(context, *args, **kwargs):
# 获取启动模式和配置文件
mode = LaunchConfiguration("mode").perform(context)
config_file = LaunchConfiguration("file").perform(context)
rows = yaml.safe_load(Path(config_file).read_text())
rows = [row for row in rows if mode in row["mode"]]
# 创建所有监控节点
topic_monitor_nodes = [create_topic_monitor_node(row) for row in rows]
topic_monitor_names = [create_topic_monitor_name(row) for row in rows]
# 组织参数
topic_monitor_param = defaultdict(lambda: defaultdict(list))
for row in rows:
topic_monitor_param[row["type"]][row["module"]].append(create_topic_monitor_name(row))
topic_monitor_param = {name: dict(module) for name, module in topic_monitor_param.items()}
# 创建主组件节点(StateMonitor)
component = ComposableNode(
namespace="component_state_monitor",
package="component_state_monitor",
plugin="component_state_monitor::StateMonitor",
name="component",
parameters=[{"topic_monitor_names": topic_monitor_names}, topic_monitor_param],
)
# 创建容器,并将所有ComposableNode添加到容器中
container = ComposableNodeContainer(
namespace="component_state_monitor",
name="container",
package="rclcpp_components",
executable="component_container",
composable_node_descriptions=[component] + topic_monitor_nodes, # 将监控节点加入容器
output="screen",
)
return [container]
def generate_launch_description():
return launch.LaunchDescription(
[
DeclareLaunchArgument("file"),
DeclareLaunchArgument("mode"),
OpaqueFunction(function=launch_setup),
]
)代码修改后运行可发现监控 node 成功被放入 container 容器中在同一个进程中运行。
但是检查进程占用情况发现 component_state_monitor 进程总占用在 70

修改参数列表中的 window_size 与 update_rate,将其从默认的 10 调小至 2 后,占用可下降至 15

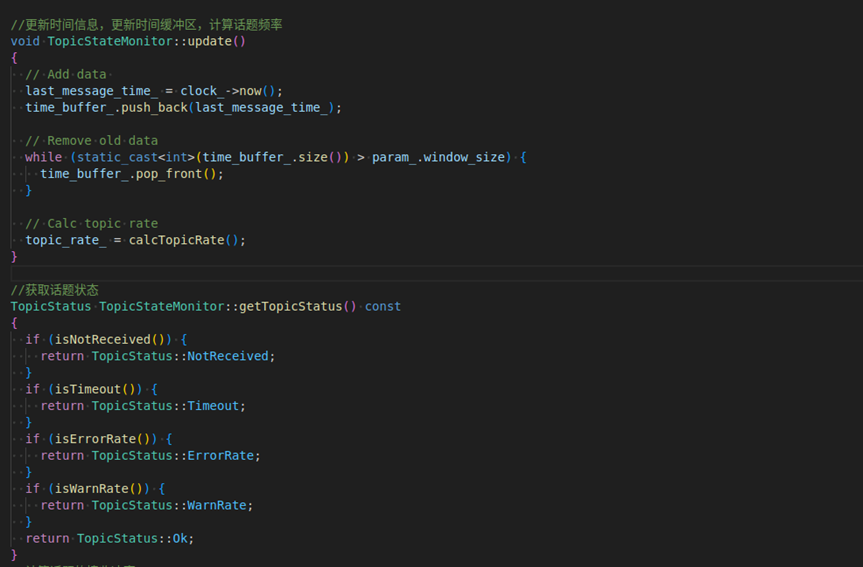
经分析,TopicStateMonitor 的逻辑本身相对简单,只是维护一个时间戳队列、计算话题接收速率,并根据阈值进行状态判断。单独看这段代码,性能开销并不大,主要是一些基本的内存操作(push_back、pop_front)、时间计算和简单的条件判断。这些操作本身不是CPU占用的主要来源。
然而,当有 15个 这样的监控节点,每个节点都在高频率地接收消息并调用 update() 函数时,整体系统的CPU使用率就可能显著增加。由于 Autoware 系统繁杂臃肿,消息的频率不太好手动控制。为了控制变量研究消息频率与数量对监控模块占用系统资源的情况,于是手动创建一些节点,观察不同 topic 数量、频率与 QoS 策略下的系统资源占用情况。
测试编写脚本创建多个发布者发布 std_msgs/msg/String 格式的话题,然后启动 topic_state_monitor,其中 window_size 设为 2、update_rate 设为 1。之后对 topic_state_monitor 进程的 CPU 占用率进行监控 120秒,每秒测两次,将测试结果绘制成表格如下所示:
| 影响因素 | Topic数量 | Topic频率 | best_effort | transient_local | 平均占用率 | 最小占用率 | 最大占用率 | Topic频率对占用率的影响 |
|---|---|---|---|---|---|---|---|---|
| 15 | 5 | false | true | 3.55 | 2.0 | 5.0 | ||
| 15 | 10 | false | true | 4.53 | 3.0 | 6.0 | ||
| 15 | 15 | false | true | 5.63 | 3.0 | 7.0 | ||
| 15 | 20 | false | true | 8.44 | 4.0 | 12.0 | ||
| 15 | 35 | false | true | 10.23 | 4.0 | 14.0 | ||
| 15 | 40 | false | true | 11.36 | 8.0 | 16.0 | ||
| 15 | 45 | false | true | 13.87 | 10.0 | 18.0 | ||
| 15 | 50 | false | true | 14.30 | 10.0 | 18.0 | ||
| QoS策略对占用率的影响 | 15 | 50 | false | false | 12.47 | 8.0 | 16.0 | |
| 15 | 50 | true | true | 11.42 | 8.0 | 16.0 | ||
| 15 | 50 | true | false | 11.17 | 6.0 | 16.0 | ||
| Topic数量对占用率的影响 | 20 | 50 | true | false | 16.30 | 10.0 | 22.0 | |
| 10 | 50 | true | false | 6.54 | 4.0 | 12.0 | ||
| 5 | 50 | true | false | 4.54 | 2.0 | 8.0 |
将表格绘制成折线图如下所示:
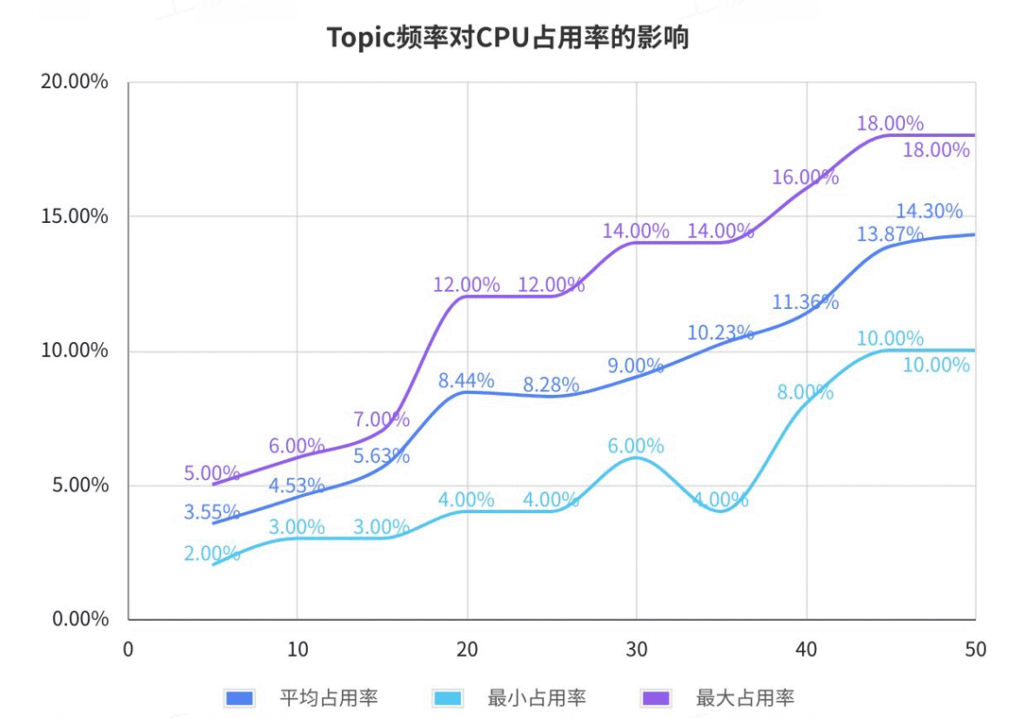
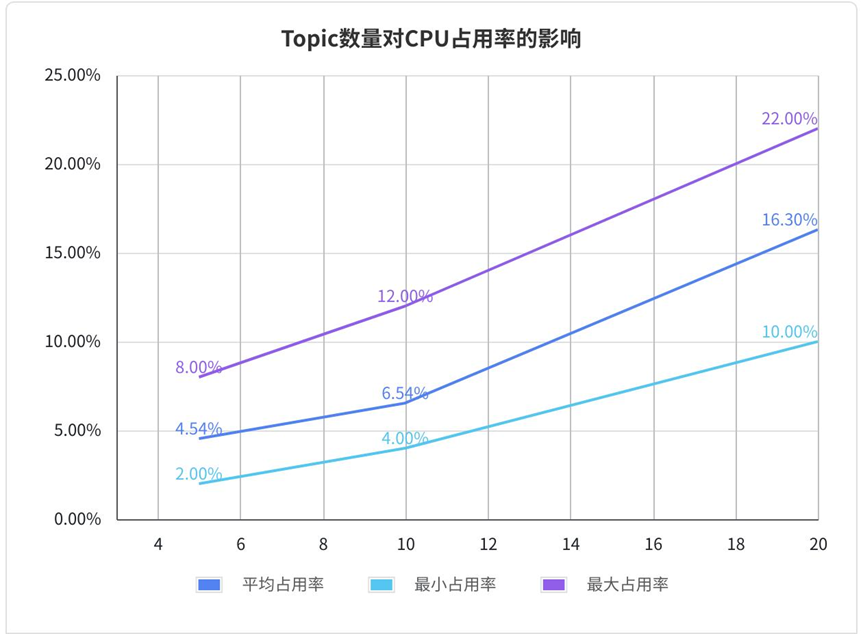
由表格数据可以得出结论:
- Topic 数量与频率的增加会增加
topic_state_monitor模块对系统的占用。如果以 15- 同时,QoS 策略也会对系统占用产生影响。设置
best_effort为true,即不使用 reliable 可靠性传输策略;设置transient_local为false,即不使用 Volatile 持久性 QoS 策略。这样可以牺牲一点消息传输的可靠性来换取更低的资源占用。 - 同时,QoS 策略也会对系统占用产生影响。设置
小结
topic_state_monitor 模块可针对任意类型的 topic 生成一个 node 去监控 topic 的状态,通用性强。但如果需要监控过多高频的 Topic 消息可能会导致进程开销大。因此 Autoware 中对进行监控的 topic 进行了模块化分类处理,根据不同的应用场景选择性地监控关键模块的关键话题。例如,定位模块着重关注 map 到 base_link 的 tf 转换是否正常,控制模块着重关注发布的 control_cmd 控制 topic 是否正常。